Python Celery & RabbitMQ Tutorial
Celery is an asynchronous task queue. It can be used for anything that needs to be run asynchronously. For example, background computation of expensive queries. RabbitMQ is a message broker widely used with Celery. In this tutorial, we are going to have an introduction to basic concepts of Celery with RabbitMQ and then set up Celery for a small demo project. At the end of this tutorial, you will be able to setup a Celery web console monitoring your tasks.
Basic Concepts
Let’s use the below graphic to explain the foundations:
Broker
The Broker (RabbitMQ) is responsible for the creation of task queues, dispatching tasks to task queues according to some routing rules, and then delivering tasks from task queues to workers.
Consumer (Celery Workers)
The Consumer is the one or multiple Celery workers executing the tasks. You could start many workers depending on your use case.
Result Backend
The Result Backend is used for storing the results of your tasks. However, it is not a required element, so if you do not include it in your settings, you cannot access the results of your tasks.
Recommendation
If your company is hiring a Python developer, check out this Python test prepared by our professionals. It will allow you to identify the best talents very easily!
Install Celery
First, we need to install Celery, which is pretty easy using PyPI:
$ pip install celery
Note that it would be better to do this using a virtual environment.
Choose a broker: RabbitMQ
This is where the confusion begins. Why do we need another thing called broker? It’s because Celery does not actually construct a message queue itself, so it needs an extra message transport (a broker) to do that work. You can think of Celery as a wrapper around a message broker.
In fact, you can choose from a few different brokers, like RabbitMQ, Redis, or a database (e.g., a Django database).
In this tutorial, we are using RabbitMQ as our broker because it is feature-complete, stable and recommended by Celery. In Mac OS, it is easy to install RabbitMQ using Homebrew:
$ brew install rabbitmq
# if you are using Ubuntu or Debian, try:
# sudo apt-get install rabbitmq-server
Start RabbitMQ
Homebrew will install RabbitMQ in /usr/local/sbin although some systems may vary. You can add this path to the environment variable PATH for convenient usage later. For example, open your shell startup file (eg.~/.bash_profile) and add the following line:
PATH=$PATH:/usr/local/sbin
Now we can start the RabbitMQ server using the command rabbitmq-server. You will see similar output if the RabbitMQ server starts successfully.
$ rabbitmq-server
RabbitMQ 3.5.1. Copyright (C) 2007-2014 GoPivotal, Inc.
## ## Licensed under the MPL. See http://www.rabbitmq.com/
## ##
########## Logs: /usr/local/var/log/rabbitmq/rabbit@localhost.log
###### ## /usr/local/var/log/rabbitmq/rabbit@localhost-sasl.log
##########
Starting broker... completed with 10 plugins.
Configure RabbitMQ for Celery
Before we can use RabbitMQ for Celery, we need to do some configurations for RabbitMQ. Briefly speaking, we need to create a virtual host and user, then set user permissions so it can access the virtual host.
# add user 'jimmy' with password 'jimmy123'
$ rabbitmqctl add_user jimmy jimmy123
# add virtual host 'jimmy_vhost'
$ rabbitmqctl add_vhost jimmy_vhost
# add user tag 'jimmy_tag' for user 'jimmy'
$ rabbitmqctl set_user_tags jimmy jimmy_tag
# set permission for user 'jimmy' on virtual host 'jimmy_vhost'
$ rabbitmqctl set_permissions -p jimmy_vhost jimmy ".*" ".*" ".*"
Note that there are three kinds of operations in RabbitMQ: configure, write and read.
The ".*" ".*" ".*" string at the end of the above command means that the user “jimmy” will have all configure, write and read permissions. To find more information about permission control in RabbitMQ, you can refer to http://www.rabbitmq.com/access-control.html
A Simple Demo Project
Now let’s create a simple project to demonstrate the use of Celery. You can find the demo on Github here.
Python Celery & RabbitMQ Tutorial - Step by Step Guide with Demo and Source CodeClick To TweetProject Structure
Below is the structure of our demo project.
test_celery
__init__.py
celery.py
tasks.py
run_tasks.py
celery.py
Add the following code in celery.py:
from __future__ import absolute_import
from celery import Celery
app = Celery('test_celery',
broker='amqp://jimmy:jimmy123@localhost/jimmy_vhost',
backend='rpc://',
include=['test_celery.tasks'])
Here, we initialize an instance of Celery called app, which is used later for creating a task.
The first argument of Celery is just the name of the project package, which is “test_celery”.
The broker argument specifies the broker URL, which should be the RabbitMQ we started earlier. Note that the format of broker URL should be:
transport://userid:password@hostname:port/virtual_host
For RabbitMQ, the transport is amqp.
The backend argument specifies a backend URL. A backend in Celery is used for storing the task results. So if you need to access the results of your task when it is finished, you should set a backend for Celery.
rpc means sending the results back as AMQP messages, which is an acceptable format for our demo. More choices for message formats can be found here.
The include argument specifies a list of modules that you want to import when Celery worker starts. We add the tasks module here so that the worker can find our task.
tasks.py
In this file, we define our task longtime_add:
from __future__ import absolute_import
from test_celery.celery import app
import time
@app.task
def longtime_add(x, y):
print 'long time task begins'
# sleep 5 seconds
time.sleep(5)
print 'long time task finished'
return x + y
You can see that we import the app defined in the previous celery module and use it as a decorator for our task method. Note that app.task is just a decorator. In addition, we sleep 5 seconds in our longtime_add task to simulate a time-expensive task:)
run_tasks.py
After setting up Celery, we need to run our task, which is included in the runs_tasks.py:
from .tasks import longtime_add
import time
if __name__ == '__main__':
result = longtime_add.delay(1,2)
# at this time, our task is not finished, so it will return False
print 'Task finished? ', result.ready()
print 'Task result: ', result.result
# sleep 10 seconds to ensure the task has been finished
time.sleep(10)
# now the task should be finished and ready method will return True
print 'Task finished? ', result.ready()
print 'Task result: ', result.result
Here, we call the task longtime_add using the delay method, which is needed if we want to process the task asynchronously. In addition, we keep the results of the task and print some information. The ready method will return True if the task has been finished, otherwise False. The result attribute is the result of the task (“3” in our case). If the task has not been finished, it returns None.
Start Celery Worker
Now, we can start Celery worker using the command below (run in the parent folder of our project folder test_celery):
$ celery -A test_celery worker --loglevel=info
You will see something like this if Celery successfully connects to RabbitMQ:
$ celery -A test_celery worker --loglevel=info
-------------- celery@zhangmatoMacBook-Pro.local v3.1.23 (Cipater)
---- **** -----
--- * *** * -- Darwin-15.4.0-x86_64-i386-64bit
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: test_celery:0x10d9b0d10
- ** ---------- .> transport: amqp://jimmy:**@localhost:5672/jimmy_vhost
- ** ---------- .> results: rpc://
- *** --- * --- .> concurrency: 4 (prefork)
-- ******* ----
--- ***** ----- [queues]
-------------- .> celery exchange=celery(direct) key=celery
[tasks]
. test_celery.tasks.longtime_add
[2016-04-24 22:41:20,297: INFO/MainProcess] Connected to amqp://jimmy:**@127.0.0.1:5672/jimmy_vhost
[2016-04-24 22:41:20,310: INFO/MainProcess] mingle: searching for neighbors
[2016-04-24 22:41:21,321: INFO/MainProcess] mingle: all alone
[2016-04-24 22:41:21,374: WARNING/MainProcess] celery@zhangmatoMacBook-Pro.local ready.
Run Tasks
In another console, input the following (run in the parent folder of our project folder test_celery):
$ python -m test_celery.run_tasks
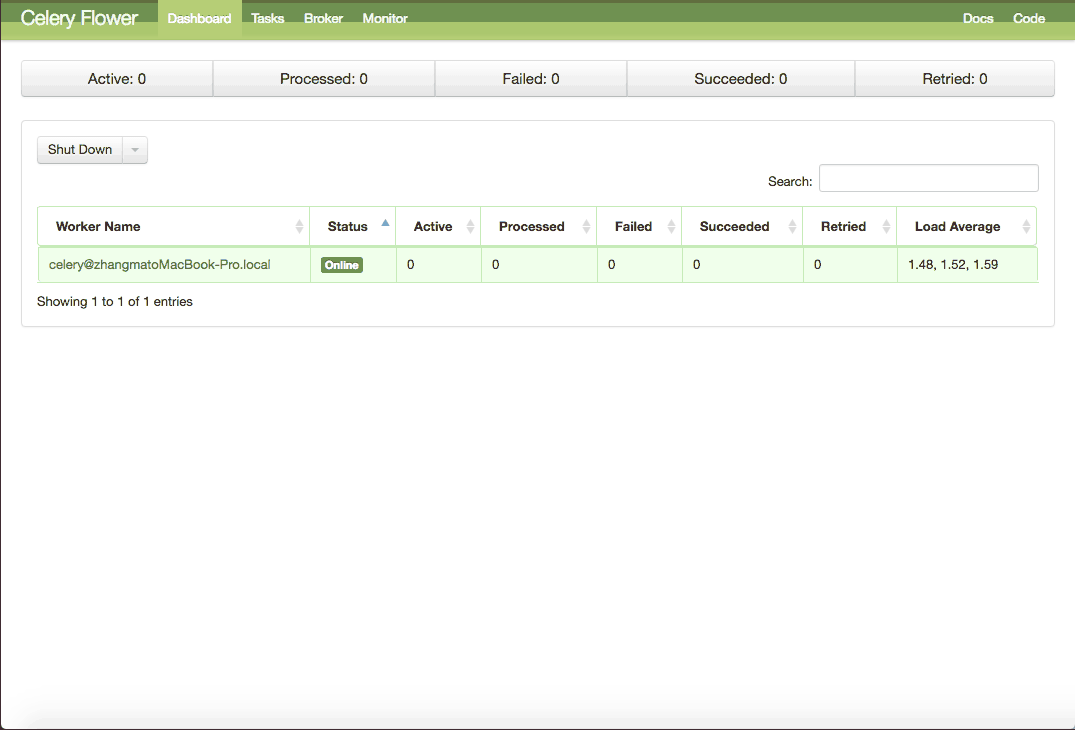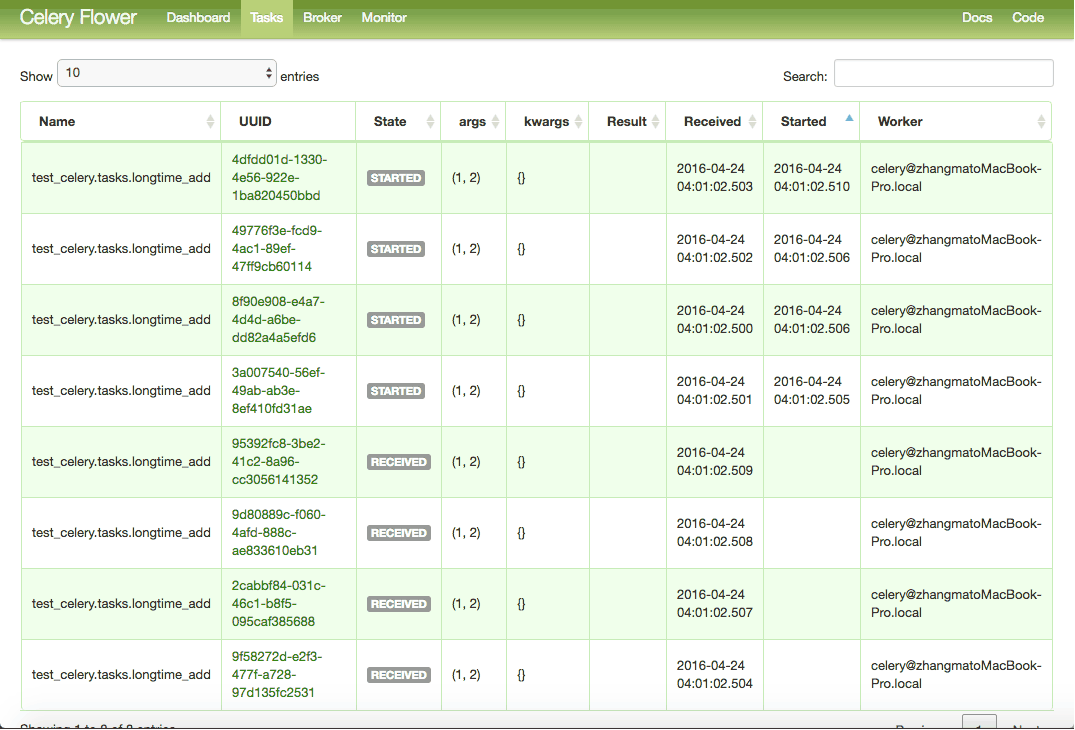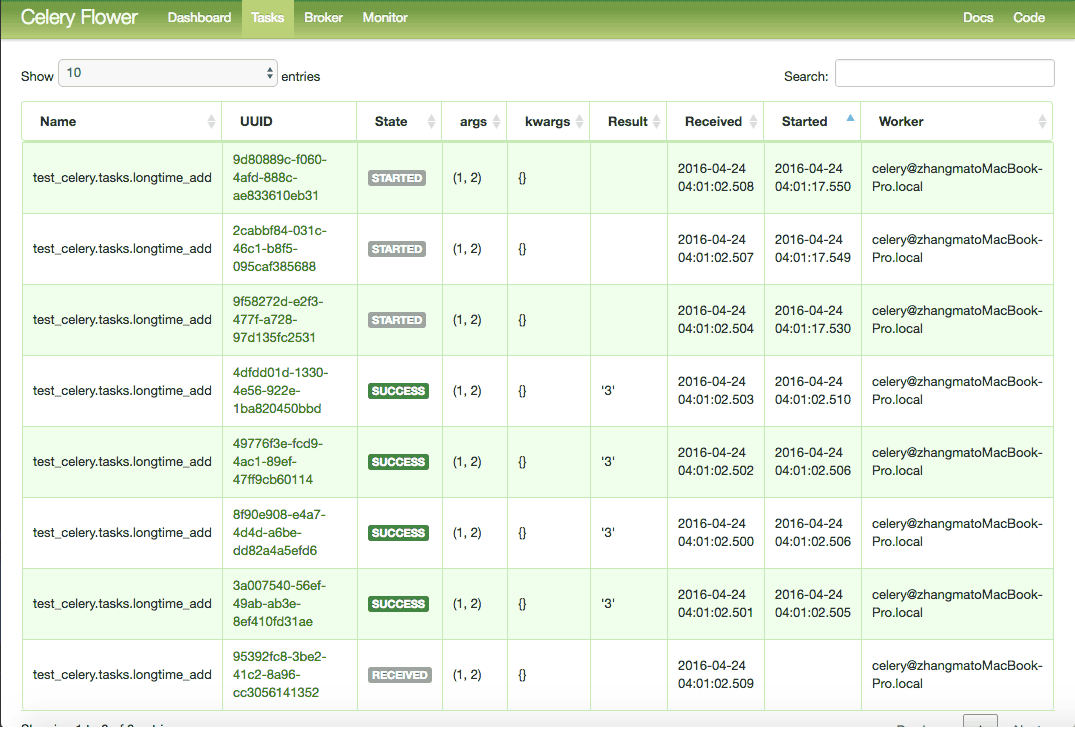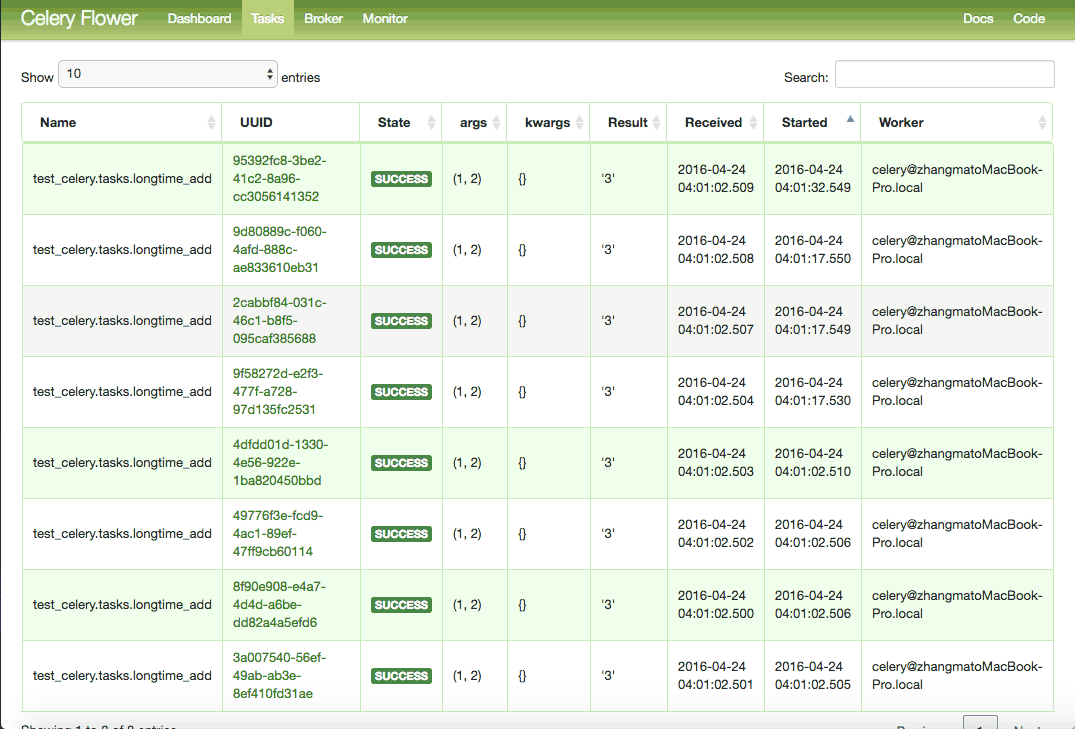
Now if you look at the Celery console, you will see that our worker received the task:
[2016-04-24 22:59:16,508: INFO/MainProcess] Received task: test_celery.tasks.longtime_add[25ba9c87-69a7-4383-b983-1cefdb32f8b3]
[2016-04-24 22:59:16,508: WARNING/Worker-3] long time task begins
[2016-04-24 22:59:31,510: WARNING/Worker-3] long time task finished
[2016-04-24 22:59:31,512: INFO/MainProcess] Task test_celery.tasks.longtime_add[25ba9c87-69a7-4383-b983-1cefdb32f8b3] succeeded in 15.003732774s: 3
As you can see, when our Celery worker received a task, it printed out the task name with a task id (in the bracket):
Received task: test_celery.tasks.longtime_add[7d942984-8ea6-4e4d-8097-225616f797d5]
Below this line is two lines that were printed by our task longtime_add, with a time delay of 5 seconds:
long time task begins
long time task finished
The last line shows that our task was finished in about 5 seconds and the task result is 3:
Task test_celery.tasks.longtime_add[7d942984-8ea6-4e4d-8097-225616f797d5] succeeded in 5.025242167s: 3
In the current console, you will see the following output:
$ python -m test_celery.run_tasks
Task finished? False
Task result: None
Task finished? False
Task result: None
This is the expected behavior. At first, our task was not ready, and the result was None. After 10 seconds, our task has been finished and the result is 3.
Monitor Celery in Real Time
Flower is a real-time web-based monitor for Celery. Using Flower, you could easily monitor your task progress and history.
We can use pip to install Flower:
$ pip install flower
To start the Flower web console, we need to run the following command (run in the parent folder of our project folder test_celery):
$ celery -A test_celery flower
Flower will run a server with default port 5555, and you can access the web console at http://localhost:5555.

Conclusion
Celery is easy to set up when used with the RabbitMQ broker, and it hides the complex details of RabbitMQ. You can find the full set code of demo project above on Github.
Python Celery & RabbitMQ Tutorial - Step by Step Guide with Demo and Source CodeClick To TweetJimmy Zhang is a software developer experienced in backend development with Python and Django. You could find more about him on his website http://www.catharinegeek.com/
Coding skills assessment
If you're looking to hire software engineers and want to ensure that you only interview qualified candidates, we've created coding tests that can significantly simplify your hiring process:
I love your blog.. ery nice colors & theme. Did yoou make this website yourself
or did you hire someone to ddo it for you? Plz respond as I’m looking to
construct my own blog and would like to find out where u got
this from. thanks a lot
get wordpress and some themes… good luck
Hurrah! At last I got a weblog from where I know how to truly get helpful facts concerning
my study and knowledge.
Great, clear HOWTO. Thanks for writing.
I installed rabbitmq seperately in windows platform, followed as per your tutorial… but I am getting the following
Traceback
————– celery@WKC001335224 v4.0.0 (latentcall)
—- **** —–
— * *** * — Windows-7-6.1.7601-SP1 2016-11-09 19:34:17
— * – **** —
– ** ———- [config]
– ** ———- .> app: assigner:0x352ce90
– ** ———- .> transport: amqp://kavin:**@localhost:5672//kavin_host
– ** ———- .> results: rpc://
– *** — * — .> concurrency: 12 (prefork)
— ******* —- .> task events: OFF (enable -E to monitor tasks in this worker)
— ***** —–
————– [queues]
.> celery exchange=celery(direct) key=celery
[2016-11-09 19:34:17,686: CRITICAL/MainProcess] Unrecoverable error: TypeError(‘must be integer, no
t _subprocess_handle’,)
Traceback (most recent call last):
File “c:\users\murugk7\envs\celery_test\lib\site-packages\celery\worker\worker.py”, line 203, in sta
rt
self.blueprint.start(self)
File “c:\users\murugk7\envs\celery_test\lib\site-packages\celery\bootsteps.py”, line 119, in start
step.start(parent)
File “c:\users\murugk7\envs\celery_test\lib\site-packages\celery\bootsteps.py”, line 370, in start
return self.obj.start()
File “c:\users\murugk7\envs\celery_test\lib\site-packages\celery\concurrency\base.py”, line 131, in
start
self.on_start()
File “c:\users\murugk7\envs\celery_test\lib\site-packages\celery\concurrency\prefork.py”, line 112,
in on_start
**self.options)
File “c:\users\murugk7\envs\celery_test\lib\site-packages\billiard\pool.py”, line 1008, in __init__
self._create_worker_process(i)
File “c:\users\murugk7\envs\celery_test\lib\site-packages\billiard\pool.py”, line 1117, in _create_w
orker_process
w.start()
File “c:\users\murugk7\envs\celery_test\lib\site-packages\billiard\process.py”, line 122, in start
self._popen = self._Popen(self)
File “c:\users\murugk7\envs\celery_test\lib\site-packages\billiard\context.py”, line 383, in _Popen
return Popen(process_obj)
File “c:\users\murugk7\envs\celery_test\lib\site-packages\billiard\popen_spawn_win32.py”, line 64, i
n __init__
_winapi.CloseHandle(ht)
TypeError: must be integer, not _subprocess_handle
(celery_test) C:\kavin\Assigner\assigner>Traceback (most recent call last):
File “”, line 1, in
File “c:\users\murugk7\envs\celery_test\lib\site-packages\billiard\spawn.py”, line 159, in spawn_mai
n
new_handle = steal_handle(parent_pid, pipe_handle)
File “c:\users\murugk7\envs\celery_test\lib\site-packages\billiard\reduction.py”, line 121, in steal
_handle
_winapi.PROCESS_DUP_HANDLE, False, source_pid)
WindowsError: [Error 87] The parameter is incorrect
Please help me to clear this
I am getting the above Traceback when I am executing the command:
“celery -A assigner worker”
where assigner is my project name
I get the same error as Kavin
http://docs.celeryproject.org/en/latest/whatsnew-4.0.html#removed-features
Microsoft Windows is no longer supported.
Hi,
everything works perfectly on CentOS7 as long as I do not start “flower”.
When I start celery with the flower argument no tasks are created and nothing is shown in the flower UI.
Python just says:
Task finished? False
Task result: None
Task finished? False
Task result: None
and celery:
celery -A test_celery flower
[I 170201 10:07:01 command:136] Visit me at http://localhost:5555
[I 170201 10:07:01 command:141] Broker: amqp://tju:**@localhost:5672/tju_vhost
[I 170201 10:07:01 command:144] Registered tasks:
[u’celery.accumulate’,
u’celery.backend_cleanup’,
u’celery.chain’,
u’celery.chord’,
u’celery.chord_unlock’,
u’celery.chunks’,
u’celery.group’,
u’celery.map’,
u’celery.starmap’,
u’test_celery.tasks.longtime_add’]
[I 170201 10:07:01 mixins:224] Connected to amqp://tju:**@127.0.0.1:5672/tju_vhost
[W 170201 10:07:03 control:44] ‘stats’ inspect method failed
[W 170201 10:07:03 control:44] ‘active_queues’ inspect method failed
[W 170201 10:07:03 control:44] ‘registered’ inspect method failed
[W 170201 10:07:03 control:44] ‘scheduled’ inspect method failed
[W 170201 10:07:03 control:44] ‘active’ inspect method failed
[W 170201 10:07:03 control:44] ‘reserved’ inspect method failed
[W 170201 10:07:03 control:44] ‘revoked’ inspect method failed
[W 170201 10:07:03 control:44] ‘conf’ inspect method failed
As soon as I remove the “flower” argument the tasks which I put in earlier are processed.
so not sure why this happens, but it seems it has something to do with this flower ui
oh please ignore … I just realized that I need to run the flow command in addition to the previous celery command.
Now i need to set a task as cron job, how to do it
Awesome post!
How the celery flower web UI reads the task information, whether it is from the RabbitMQ or from any persistent location ?
Very Informative Post…
but I have a question here: After complition of task, on celery console the output is 3 but on the curent console(from where the task ha sbeen called) it shows None. Why?
I have followd the post and did everything on my system and there also a i am getting problem.
Please explain.
Nice job with the tutorial. I believe RabbitMQ needs to be installed only on the Broker, while Celery needs to be installed on both the Broker and the Consumer. Only question in my mind after reading the tutorial…
This is awesome!!
Thank you for simple demo.
Hie Blogger,
I followed your steps and rabbit-mq server started successfully.Configure rabbit-mq for celery to be done in another cmd prompt or the same cmd-prompt where we have started rabbit-mq server? I just tried it in another command prompt, but i am getting this below error:
C:\Program Files\RabbitMQ Server\rabbitmq_server-3.7.13\sbin>rabbitmqctl add_use
r jimmy jimmy123
The directory name is invalid.
The filename, directory name, or volume label syntax is incorrect.
** (MatchError) no match of right hand side value: {:error, {:node_name, :hostna
me_not_allowed}}
(rabbitmqctl) lib/rabbitmq/cli/core/helpers.ex:32: RabbitMQ.CLI.Core.Helpers
.normalise_node/2
(rabbitmqctl) lib/rabbitmqctl.ex:239: RabbitMQCtl.merge_defaults_node/1
(rabbitmqctl) lib/rabbitmqctl.ex:232: RabbitMQCtl.merge_all_defaults/1
(rabbitmqctl) lib/rabbitmqctl.ex:103: RabbitMQCtl.exec_command/2
(rabbitmqctl) lib/rabbitmqctl.ex:45: RabbitMQCtl.main/1
(elixir) lib/kernel/cli.ex:105: anonymous fn/3 in Kernel.CLI.exec_fun/2
dvfpjaapmyallvijzrwyhjynkuajte